
Wasm compression benchmarks and the cost of missing compression APIs
Published on:Table of Contents
Lack of transparent compression
IndexedDB, the Cache API, and network requests will not transparently compress data, and I think this is a problem.
Testing was done on Chrome and behavior may vary by browser.
Let’s say we want a function to persist a large binary payload. Here’s an IndexedDB solution using the idb-keyval library to simplify the API:
import { set } from "idb-keyval";
export async function setRawData(data: Uint8Array) {
await set("data", data);
}
And here’s the Cache API solution:
export async function persistDataCache(data: Uint8Array) {
const cache = await caches.open("my-cache");
await cache.put("/data", new Response(data));
}
After executing these functions, I noted that the data was being stored uncompressed in the following directories:
%LocalAppData%\Google\Chrome\User Data\Default\IndexedDB\http_localhost_3001.indexeddb.blob\1\05
%LocalAppData%\Google\Chrome\User Data\Default\Service Worker\CacheStorage\..
I even tried getting cute and adding content encoding headers to the response to see if that would trigger compression, but to no avail:
// Adding content encoding header doesn't work :(
export async function persistDataCache2(data: Uint8Array) {
const cache = await caches.open("my-cache");
const headers = new Headers({ "Content-Encoding": "gzip" });
await cache.put("/data", new Response(data, { headers }));
}
I was initially optimistic that there might be transparent compression as browsers store compressed responses in a compressed format. But no such luck. What’s worse is that through empirical testing, storing compressed responses via Cache API aren’t compressed. If the previous article is true, then it would seem like a fetch with a force-cache may be the best avenue for accessing compressed responses, and responses only.
And in what may be the most egregious omission: client POST uploads. It’s 2023, and we, as an industry, are laser focussed on shaving bytes and milliseconds off server responses but are perfectly content with forcing clients to upload data uncompressed. Seems like such an easy win. What server can gzip compress but can’t decompress?
What’s the point?
Why do I care about storing and sending data in a compressed format?
The most obvious reason is disk space and especially network usage, but the second, more nuanced point is performance.
If a SATA SSD can sequentially read around 500 MB/s, a 100 MB file will be read in 200ms. But if we can compress the corpus to 10 MB and inflate it at 1 GB/s, the total time to read the file from disk and decompress is 120ms, which is 66% faster. In the squash compression benchmarks, there is a visual dedicated to communicating this exact point: introducing compression can be a boon for performance.
With mainstream CPUs now shipping with 6 or more cores, I think it may be safe to say that CPUs are more under-utilized than disk I/O.
This performance increase from compression is why the transparent compression for ZFS file systems is recommended. Compressing with LZ4 (or ZSTD for newer installs) saves on time and space at the cost of a marginal increase in CPU usage. And “incompressible data is detected and skipped quickly enough to avoid impacting performance” (source).
So everything should be compressed by default, right? If there’s only upsides to disk space and performance? Quora experts weigh in. Sorry for the tongue in cheek phrasing.
But it looks like unless one stores Chrome’s data on a file system with builtin compression, we’ll need to handle compression ourselves.
Compression Streams API
Until transparent compression is implemented, we’ll need to handle the compression in user space.
The easiest way is to use Chromium-only Compression Streams API:
export async function persistDataCache3(data: Uint8Array) {
const src = new Blob([data]);
const cs = src.stream().pipeThrough(new CompressionStream('gzip'));
const cache = await caches.open("my-cache");
await cache.put("/data", new Response(cs));
}
Compression streams are easy but their downsides should give one pause:
- Limited support. At the time of writing, Chromium (Chrome and Edge) only
- Since browser support is limited, there’s no builtin Typescript support
- Compression algorithms are limited to gzip/deflate, which are good but may not be optimal for all situations
- There is no way to configure the compression level
Don’t sleep on compression streams either, you won’t find a better way to incrementally stream a compressed request:
export async function sentToApi(data: Uint8Array) {
const src = new Blob([data]);
const body = src.stream().pipeThrough(new CompressionStream('gzip'));
// todo: fill out content-type
await fetch("my-url", {
method: "POST",
duplex: "half",
headers: {
"Content-Encoding": "gzip"
},
body,
});
}
There some limitations:
- Half duplex mode is required for now, this won’t be a problem unless it is expected to receive a streaming response while the streaming body is in flight. The biggest inconvenience will be sprinkling in
@ts-ignoreas the duplex property won’t be recognized by Typescript. - The request will fail on HTTP/1.x with a lovely
ERR_H2_OR_QUIC_REQUIREDerror. So no testing withnext dev. One can guard sending the request based onnextHopProtocolas shown.
DIY Compression
I can’t help but wonder if the enthusiasm towards browsers implementing the CompressionStream API has been hampered due to the existence of Wasm and high quality JS Deflate libraries like pako and fflate. We can see these exact points used as hesitation in a mozilla standards position discussion a couple years ago.
In the same discussion, a core Chromium developer lends support to having a native implementation and touched on performance:
Facebook found that the native implementation was 20x faster than JavaScript and 10% faster than WASM.
Queue the benchmarks! We’re going to find out just how accurate this is.
In addition to the two aforementioned JS libraries, our contestants were written with Rust and compiled to Wasm.
- miniz_oxide for Deflate
- Dropbox’s reimplementation of brotli in Rust
- lz4_flex for LZ4
- And Rust bindings to the official zstd library
Results
I took a 91 MB file and ran it through the gauntlet on Firefox and Chrome. Keep in mind there are many different Wasm runtimes, see this benchmark of them. And runtime performance may differ greatly depending on the underlying platform and may results may not be reflective of native performance, so be careful when making extrapolations.
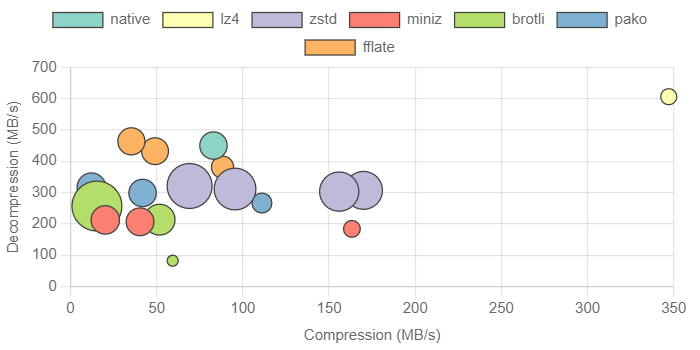
Chrome compression chart (click to enlarge)
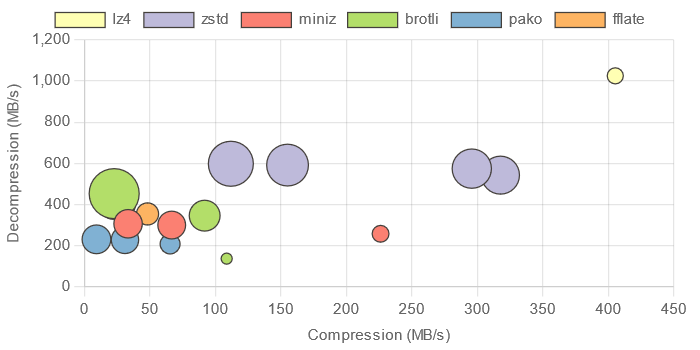
Firefox compression chart (click to enlarge)
Notes about the chart:
- They are screenshots from the benchmark site where they are interactive, so I highly recommend using the site to generate the charts
- A high compression ratio is represented by the size of the bubble
- Multiple bubbles of the same color represent different compression levels
- Chart scales are relative per run, and Firefox’s x and y scale are wider
Below is a table of the brotli compressed size of the library.
| Name | Size (Brotli’d kB) |
|---|---|
| native | 0.0 |
| lz4 | 13.9 |
| zstd | 138.6 |
| miniz | 25.2 |
| pako | 15.2 |
| fflate | 12.8 |
| brotli (read) | 137.8 |
| brotli (write) | 681.0 |
A couple of insights:
- Firefox has much better Wasm execution
- Firefox has 2x decompression throughput on lz4 (cracking 1 GB/s) and zstd, and to a lesser extent with miniz and brotli
- Firefox has wins across the board with Wasm compression too, including a 2x improvement with zstd-3
- Chrome has better JS execution
- fflate compresses 1.5x faster on Chrome
- pako and decompression benchmarks are around 20% faster on Chrome
- It’s funny, a news article from TheNewStack found the opposite performance relationship between browsers and JS vs Wasm.
While Wasm was more energy efficient and outperformed JavaScript on Google Chrome and Microsoft Edge, JavaScript did have better performance results than Wasm on Mozilla Firefox
- Out of the two JS Deflate libraries, fflate is about 1.5x faster at decompressing, though they are roughly equivalent in compression throughput at the default level with fflate performing better at higher levels.
- Comparing Wasm Deflate vs JS Deflate, in decompression, miniz is 2x faster than fflate on Firefox, while fflate is 2x faster on Chrome in compression
- Chrome’s native gzip implementation has 2x the compression throughput as fflate and around the same decompression throughput, which should still be a huge testament to the fflate implementation that JS can match native in decompression.
- Zstd level 3 scores well. Faster than all the Deflate implementations in compression and either ties or bests them in decompression. Great compression ratio (nearly 13x). The biggest downside is that 138 kB (brotli compressed) payload shouldn’t be ignored. The good news is that by default, zstd trades size for performance and there is work being done on the Rust implementation to expose this and allow creating a decompression-only zstd build. I’m curious what effect this will have. In the chromium bug tracker, a size-optimized version was reported to be 26 kB gzipped.
- While brotli has decent results, I feel that the Wasm implementation does not distinguish itself from Deflate or zstd to justify the cost of such a large payload necessary to write (a whopping 681 kB). Brotli includes a static dictionary, and I have to assume that a large chunk of the library size is due to this inclusion. Brotli was the only library that I felt was necessary to split up reporting the read and write sizes. And the size is a reason that is complicating a
new CompressionStream("br")implementation. - In comparison with the Wasm library sizes, the JS implementations are remarkably light (12-15 kB brotli’d). Only lz4 comes close at 14 kB, and I’m being generous with the Wasm sizes by omitting the JS boilerplate for initialization and marshaling which is at least 1 kB brotli’d. Wasm libraries often lose out as they need to reimplement dynamic memory allocation. I wrote about strategies one can use to avoid this cost, but it’s not easy.
In an effort to detect if there was a benefit to delivering data compressed to Wasm instead of using the browser’s native Content-Encoding decoder, I ran a small test outside of this benchmark to measure the overhead. I’m happy to report that there isn’t significant overhead in transferring large amounts of data to Wasm. So don’t abandon the Content-Encoding header. The native browser implementation is probably much more efficient than any reimplementation in userland.
Recommendations
- Keep using transparent content decoders like brotli on responses. Don’t go re-encoding assets in zstd and decompressing in userland. Even if the response data ends up being processed in Wasm, there is no overhead in marshaling uncompressed data and the native Deflate and brotli implementations are more efficient than Wasm. Re-fetch the data from cache if sporadic access is needed instead of using IndexedDB or the Cache API.
- If available, use the native Compression Streams API as it costs nothing, and will be faster than JS and Wasm implementations. Deflate has an acceptable compression ratio.
- If unavailable, there’s a chance you’re on firefox and should polyfill with the miniz-oxide Wasm implementation to reap firefox’s faster runtime
- But if Wasm is too much of an inconvenience, polyfill with
fflateor, if you prefer,pako. - lz4, brotli, and zstd Wasm implementations are highly situational, and server support may need to be tailored. But I would lean towards zstd as it scores highly in throughput, compression ratio, and isn’t obscenely large.
These recommendations are good whether it’s for file uploads or if like this netizen who stores compressed serialized state in the URL.
I have a tantalizing thought that two of these methods can be used in combination. For instance, a client can use the efficient native Compression Stream API to upload a file, which is intercepted by your favorite serverless environment or Wasm edge compute (like Fastly’s Compute@Edge or Cloudflare Workers). There at the edge, the file is transcoded with brotli for an improved compression ratio. Ideally, this transcoding could be done concurrently with validation, parsing, and any db queries related to the file.
I used brotli in the above example in the assumption that the user may download the file, so we’d want to take advantage of the browser automatically handling the Content-Encoding. So despite brotli not scoring as well as zstd, it can oftentimes be more practical for a given use case.
I won’t be proclaiming a winner between zstd and brotli. They are both very impressive. There’s an interesting exchange between a core developer of zstd, Nick Terrell, and an author behind brotli, Dr. Jyrki Alakuijala. They go back and forth about the merits of their respective algorithms. In a more recent comment, Dr Alakuijala offers insight on why they continue to praise brotli. I’m not eloquent enough to properly distill the viewpoints, but it is clear the teams behind zstd and brotli are passionate so I’ll leave you, dear reader, with these resources for your leisure. All I can say is that I ran the benchmarks, as fair as I could, to the best of my abilities, and am satisfied.
Future Work
Benchmarks are never complete. And I’m sure others have thoughts like:
- How do other Wasm Deflate implementations fare like libdeflate and cloudflare’s zlib? And even though it’s reported that there is no difference between the Rust reimplementation of brotli and the official library, is this the case?
- What is the performance benefit to compiling Wasm with and without SIMD extensions enabled? I’ve previously written about the performance speedup one can expect with Wasm SIMD
- Why are the compression levels hard-coded and why does zstd only go up to 7?
- How does a custom brotli or zstd dictionary fare?
- How does long distance matching for zstd and brotli affect the speed and compression ratio?
- Why isn’t there a benchmark filter, so I don’t want to run every benchmark?
All shortcuts were done in the interest of time, as this already has been quite the detour. I thought I had a simple question, and now look at me.
Comments
If you'd like to leave a comment, please email [email protected]