
Avoiding allocations in Rust to shrink Wasm modules
Published on:Table of Contents
Rust lacks a runtime, enabling small .wasm sizes because there is no extra bloat included like a garbage collector. You only pay (in code size) for the functions you actually use.
We can see small Wasm sizes in action with a contrived example:
use wasm_bindgen::prelude::wasm_bindgen;
#[wasm_bindgen]
pub fn add(left: f64, right: f64) -> f64 {
left + right
}
Building with:
wasm-pack build
Constructs a binary Wasm file that can be translated into a more human readable text form (via wasm-tools):
(module
(type (;0;) (func (param f64 f64) (result f64)))
(func $tmp_wasm::add::hf4d4946fa0e6e360 (;0;) (type 0) (param f64 f64) (result f64)
local.get 0
local.get 1
f64.add
)
(memory (;0;) 17)
(global (;0;) (mut i32) i32.const 1048576)
(export "memory" (memory 0))
(export "add" (func $tmp_wasm::add::hf4d4946fa0e6e360))
)
How small! The optimized binary version is even smaller at 180 bytes.
Aside: for the duration of this post,
wasm-packis used to build the code samples, but this is where the endorsement of wasm-pack stops due to ongoing maintenance issues. Instead consider if the cli underpinningwasm-pack,wasm-bindgencli, is more appropriate. If usingwasm-pack, I always disable the builtinwasm-optstep in theCargo.toml, otherwise an outdated version will be pulled if it’s not already in the user’s path:[package.metadata.wasm-pack.profile.release] wasm-opt = false
New business requirements came in and instead of adding two numbers, we need to be able to add numbers to an ongoing summation. No worries, easy enough:
#[wasm_bindgen]
pub struct Adder {
val: f64
}
#[wasm_bindgen]
impl Adder {
#[wasm_bindgen(constructor)]
pub fn new() -> Self {
Adder { val: 0.0 }
}
#[wasm_bindgen]
pub fn add(&mut self, right: f64) {
self.val += right;
}
#[wasm_bindgen]
pub fn result(&self) -> f64 {
self.val
}
}
Now downstream clients can write code like the following:
const adder = new Adder();
adder.add(1);
console.log(adder.result()); // 1
But taking a look at the generated Wasm output shows it has ballooned to over 20 KB, a 100x increase in size.
What happened?
Printing the Wasm reveals that the vast majority of the payload is dedicated to dlmalloc; memory management.
Solution #1: switch allocators
The weight of the dlmalloc allocator is known to the Rust Wasm book, and goes on to suggest subbing in wee_alloc as the global allocator. In theory, wee_alloc is great. It’s a quick and painless solution that is small and fast enough when not too many allocations are needed.
Except one will receive a dependency security alert if used:
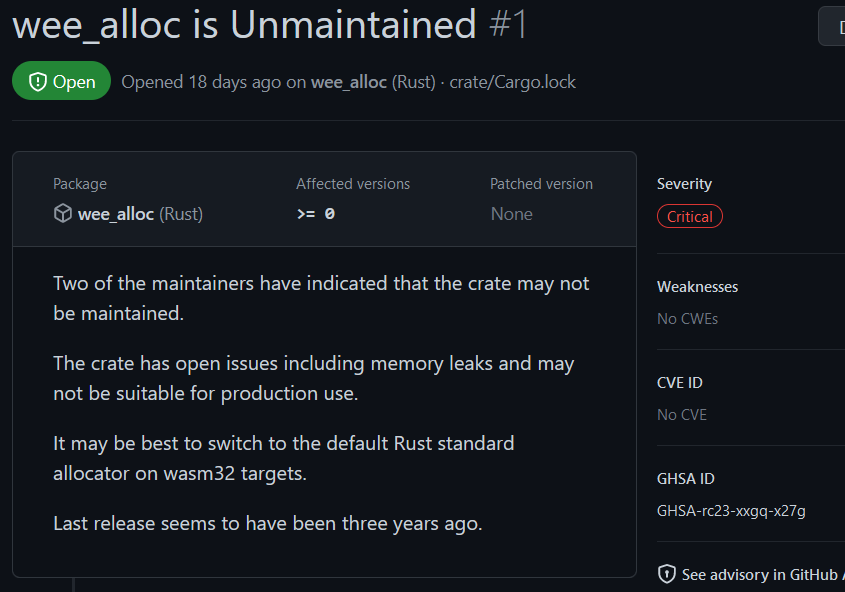
Dependabot alert for unmaintained wee_alloc
Wee_alloc is reportedly unmaintained with an open issue about a memory leak. Hence, I’d recommend avoiding wee_alloc for the time being.
Another allocator with a focus on Wasm and size is being developed: lol_alloc. It’s not currently production ready and there are some caveats surrounding multi-threading, but I’m excited to see how this allocator progresses.
Overall, it’s a bit of a shame for Rusty Wasm hobbyists who are deploying in the browser as the ecosystem of tools (eg: wasm-pack, wasm-bindgen, and wee_alloc) aren’t as vibrant as they used to be. Seems like most activity is happening for server side Wasm and spearheaded by the Bytecode Alliance, as I’m assuming that is where the money is. I’m optimistic that this work will cause the Wasm tide to rise and lift all ships.
And who knows, if Wasm dynamic linking becomes ubiquitous, dlmalloc and Rust’s standard library could be shared amongst all the Wasm modules. I’m not holding my breath, but solution #1.5 is to do nothing. It’s not worth it to bend over backwards to avoid allocations.
It can be difficult to know when allocations are present, as the module we’ve written is no_std compatible but still causes allocations. And despite wasm-bindgen declaring cargo features for a no_std build, it unfortunately is not supported. So we’re left with either declaring a null allocator to fail fast when assumptions aren’t met, or adding a test to grep symbols in the Wasm code for dlmalloc.
Solution #2: statically allocate
But let’s say we are determined to avoid allocations. We can statically allocate everything we need up front.
static mut STATE: f64 = 0.0;
#[wasm_bindgen]
pub fn new_adder() {
unsafe { STATE = 0.0 };
}
#[wasm_bindgen]
pub fn add(left: f64) {
unsafe { STATE += left };
}
#[wasm_bindgen]
pub fn result() -> f64 {
unsafe { STATE }
}
And then we can create a wrapper in Javascript.
class Adder {
constructor() {
wasm.new_adder();
}
add = (left: number) => wasm.add(left);
result = () => wasm.result();
}
This solution probably leaves an unsavory feeling of disgust as there can only be one instance at a time.
A partial workaround is to statically allocate multiple blank states, ready to go, but there will always be a limit. Not to mention a significant amount of unsafe code in order to avoid all runtime assertions which would bring in allocations, but it is doable and it does work as shown below:
// Support up to 1000 concurrent states
static mut STATES: [Option<f64>; 1000] = [None; 1000];
#[wasm_bindgen]
pub fn new_adder() -> i32 {
for idx in 0..unsafe { STATES.len() } {
let elem = unsafe { STATES.get_unchecked_mut(idx) };
if elem.is_none() {
elem.replace(0.0);
return idx as i32;
}
}
-1
}
#[wasm_bindgen]
pub fn add(left: f64, idx: usize) {
let elem = unsafe { STATES.get_unchecked_mut(idx) };
unsafe { *elem.as_mut().unwrap_unchecked() += left } ;
}
#[wasm_bindgen]
pub fn result(idx: usize) -> f64 {
// result consumes the state so there'll need to be
// something on the JS side that ensures this isn't
// called more than once.
let elem = unsafe { STATES.get_unchecked_mut(idx) };
let opt = elem.take();
unsafe { opt.unwrap_unchecked() }
}
With a JS wrapper of:
class Adder {
private idx: number;
constructor() {
this.idx = new_adder();
if (this.idx === -1) {
throw new Error("hit max limit of concurrent adders");
}
}
add = (left) => add(left, this.idx);
result = () => result(this.idx);
}
The result is about 500 bytes, which can be stripped down to 350.
I’m fairly certain Wasm instances can’t be shared across web workers, so we don’t have to stress about a data race between the checking of a state slot and assignment. But if I’m incorrect (and I’ll admit that could be), and there is a race, I imagine it’s solvable with a simple spinlock.
Though this solution does give some intuition about why our initial struct solution causes allocations when wasm-bindgen is used on a struct. We have to store state somewhere and if we need an arbitrary number of states, the logical place to house them is on the heap. This is shown in wasm-bindgen internal docs via the Box::new which allocates memory on the heap.
Solution #3: manually manage memory
The third solution revolves around manipulating WebAssembly.Memory, which is the most flexible way for JS and Wasm to communicate. Lin Clark has a good article about memory and Wasm, but essentially we’ll be reading and writing bytes from a large shared array.
We can see it in action with our example. Let’s say that Wasm didn’t natively support 64 bit floating point numbers, so we aren’t able to return an f64. Instead, if given a buffer to write to, we can emulate it by calculating the byte representation of the result.
#[wasm_bindgen]
pub fn result(idx: usize, data: *mut u8, len: usize) {
let elem = unsafe { STATES.get_unchecked_mut(idx) };
let opt = elem.take();
let out = unsafe { opt.unwrap_unchecked() };
let buffer = unsafe { core::slice::from_raw_parts_mut(data, len) };
unsafe { buffer.get_unchecked_mut(..8) }.copy_from_slice(&out.to_le_bytes());
}
This only adds a couple bytes to the Wasm payload.
With the Rust side primed and ready to receive a destination to write to, we configure the memory on the JS side.
class Adder {
private idx: number;
constructor() {
this.idx = new_adder();
// ... check for -1 ...
}
add = (left) => add(left, this.idx);
result = (output: Uint8Array) =>
result(this.idx, output.byteOffset, 8);
}
// Initialize wasm, and retrieve shared memory
const { memory } = await init();
// Two interleaved adders
let adder1 = new Adder();
let adder2 = new Adder();
adder1.add(1);
adder2.add(2);
// Ensure there is data to write to by growing the buffer
// by an increment 64 KiB
const prevLen = memory.grow(1);
// Create a byte array view that the result from Wasm
// will be written to
const out = new Uint8Array(memory.buffer, prevLen, 8);
// Create a data view to read out our encoded f64
const view = new DataView(out.buffer, out.byteOffset, out.byteLength);
// calculate and print results
adder1.result(out);
console.log(view.getFloat64(0, true));
adder2.result(out);
console.log(view.getFloat64(0, true));
The next step would be to move the statically allocated state to being dynamically stored on this linear memory. The example above is far from complete. We’d need bookkeeping to reap discarded adders and to know when we are out of space and need further growth.
The good news is that we know our state is 8 bytes and the return value is 8 bytes, so we can exploit that to simplify bookkeeping.
To be clear, one can reference this shared memory in Rust via wasm-bindgen::memory and grow it with wasm::memory_grow. This is how Rust allocators for Wasm are written, but if I’m writing a pseudo-allocator (a phrase I’d never thought I’d write), I’d rather write it in JS for a few reasons:
- Less chance of accidentally pulling in
dlmallocon the Rust side - Easier to share the allocator with other Wasm modules
- Probably less code to write and ship to the user
It won’t be easy but it would offer the best of both worlds, no arbitrary limits without needing to pull in a fully fledged and general-purpose allocator.
For more information on working with Wasm Memory:
- Passing arrays between wasm and JavaScript
- WebAssembly Linear Memory on Wasm By Example
Real world results
I applied these solutions to a hashing project of mine: highwayhasher, which is an isomorphic library for computing the HighwayHash.
I previously had been using wee_alloc, but I figure it was time for me to search for another solution.
| Solution | Compressed Wasm (KB) |
|---|---|
| baseline (wee_alloc) | 10.5 |
| dlmalloc | 14.2 |
| lol_alloc | 10.0 |
| static | 2.79 |
The static allocation is over 5x smaller than if I had gone with the standard allocator.
It wasn’t easy, though.
By far the hardest part of this migration was removing panics. The Rust Wasm book wasn’t lying when it said “this is definitely easier said than done”. It involved looking at the emitted assembly with cargo-show-asm and trying to figure out why bound checks persisted on certain slice indexing operations.
The best solution I came up with is to enforce invariants at runtime that will fallback to a default value in release mode. For instance, there’s an internal buffer that keeps track of how much of the buffer is used and allows clients to query it. Well, even though all code paths guarantee a position that is valid, Rust feels like we can’t be too sure, so we have to sprinkle some extra guard clauses:
#[derive(Default, Debug, Clone, Copy)]
pub struct HashPacket {
buf: [u8; PACKET_SIZE],
buf_index: usize,
}
impl HashPacket {
#[inline]
pub fn as_slice(&self) -> &[u8] {
if self.buf_index > self.buf.len() {
debug_assert!(false, "buf index can't exceed buf length");
&self.buf
} else {
&self.buf[..self.buf_index]
}
}
}
Once that was finished, I arrived at a portable hashing solution that was 100% pure stable Rust, zero unsafe, zero allocations, and Rust could prove to itself that panics were impossible in release mode. It’s almost ironic then how much unsafe is needed at the Rust and Wasm border, but there’s not much we can do to assuage the compiler without it introducing code to handle panics.
For the Wasm, I statically allocated placeholders (ie: MaybeUninit) for enough hashers to fit within a Wasm memory page size. Thus, there is a maximum number of concurrent hashers objects one can have, and right now it is about 300. I haven’t decided if it is worth exposing the max to JS, but it’d look like:
const ELEM_SIZE: usize = core::mem::size_of::<HighwayHasher>();
const PAGE_SIZE: usize = 65536;
const MAX_INSTANCES: usize = PAGE_SIZE / ELEM_SIZE;
static mut STATES: [MaybeUninit<HighwayHasher>; MAX_INSTANCES] =
unsafe { MaybeUninit::uninit().assume_init() };
#[wasm_bindgen]
pub fn max_instances() -> usize {
MAX_INSTANCES
}
If one did hit the instance ceiling, I’d first suggest an object pool in Javascript, otherwise I’m not opposed to increasing the static allocation.
On the JS side, I only needed to grow the memory by a single page to hold the hash key, results, and to incrementally append data to the hasher. Though it did require more code and it may not be intuitive how everything works to new eyes or even my eyes after 6 months.
Several other nice benefits have been observed:
- Speedup in compilation time. Release builds take less than a second
- Runtime performance speedup. About 2x the throughput increase on small inputs and upwards of 10% on larger inputs.
- Unsubstantiated, but I also believe there is less memory usage overall as the single page of Wasm memory is used to incrementally append data, instead of needing to make room for it all.
I haven’t quite merged this solution in, but I’m strongly considering it.
Conclusion
Here’s the solutions we’ve covered:
- Use
dlmallocand accept the outsized footprint. - Use
wee_allocand accept the dependency alert - Use the not-yet-production-worthy
lol_alloc - Statically allocate data, but face a hard limit
- Write your own pseudo allocator with Wasm memory
No solution is without drawbacks.
As much as the web has become mocked for its bloat, I can’t help but recommend others default to using the standard and battle tested dlmalloc. Writing size optimized Wasm libraries for the browser is a niche within a niche within a niche. Most Wasm written will be in conjunction with an app or a large library, where the presence of any allocator won’t make much of a splash (and the maintenance of playing whack-a-mole with panics is too burdensome).
But if you are interested in writing Wasm libraries, I’ve previously published some thoughts on the matter based on my experience.
2025 edit: Talc is a new allocator that has entered the scene. According to benchmarks, it is both smaller and faster than dlmalloc. I’ve successfully swapped to talc in Wasm applications – however the size and performance differences weren’t large enough to make the change permanent. For libraries and certain workloads, I can see talc being attractive, so I recommend at least trying it out.
Comments
If you'd like to leave a comment, please email [email protected]
Nice blog - I’m the one who wrote the security advisory :)
I neglected to mention heapless just ought to mention https://docs.rs/heapless/latest/heapless/
Also lol_alloc has different modes via features w/ size differences and the person behind it said they will address any issues if someone decides to seriously test it and willing to take it to prod
Cheers
Thanks for pointing out heapless, it does a great job of straddling the two worlds.
For lol_alloc, you’re talking about the different allocators, right? Like
FailAllocatorandFreeListAllocator? Yeah it is nice to have options.I wanted to point out another interesting allocator https://github.com/sfbdragon/talc
Thanks Michel! I updated the article to mention that talc is a solid option, and I’ve been able to successfully swap it in in Wasm applications. Though it wasn’t permanently adopted, you can’t go wrong with talc.