
Writing a high performance TLS terminating proxy in Rust
Published on:Table of Contents
I feel like I don’t write about the Rust language that often, but it turns out today is my 2nd anniversary of dabbling in Rust. Exactly two years ago, I wrote a post about processing arbitrary amount of data in Python where I benchmarked a Python csv solution against Rust (spoiler, Rust is faster). Since then, Rust has only been mentioned in passing on this blog (except for my post on creating a Rocket League Replay Parser in Rust, where I dive into not only how to create a parser with nom, but what the replay format looks like). Well, today will be all about creating a TLS termination proxy. Keep in mind, while I have a decent intuition, I still consider myself new to Rust (I still fight with the borrow checker and have to keep reminding myself what move lambdas do)
TLS Termination Proxy
Some languages have notoriously bad TLS implementations, which can be offputting to those that are looking to secure an app or site. One can put their app behind one of the big juggernauts (Apache, Nginx, HAProxy), which can do TLS termination along with hundreds of other features. I recommend using them wholeheartedly and I personally use them, but when only TLS termination is desired, these can be excessive. Hence the perfect opportunity to write a lightweight and speedy TLS implementation.
When implementing any kind of proxy, one has to determine how much content of the request is needed to proxy correctly. A layer 7 proxy would, for instance, read the HTTP url and headers (and maybe even the body) before proxying to the app. These proxies can even modify the requests, like adding the X-Forwarded-For, so the client IP address isn’t lost at the proxy. As one can imagine, this is more computationally intense than blindly handing requests from A directly to B. Since this project is more of an experiement than anything, I went with the blind approach! The advantage of a blind proxy (sometimes known as a dumb proxy) is that they are protocol agnostic and can work with any type of application data.
Note that even dumb proxies can forward client addresses to downstream services using the PROXY protocol initially championed by HAProxy. This is something that I could look to implement in the future, as it is simply a few additional bytes sent initially to the server.
Beside performance, a TLS proxy can bring other benefits. Since the use case is so focussed, it would be relatively easy to bring features such as structured logging or metrics. One wouldn’t have to reimplement the solution for “what’s the throughput for each client” for each new application. Just stick the the TLS proxy in front of any app that needs those answers.
The Design
Here’s the design, one could say it’s pretty simple:
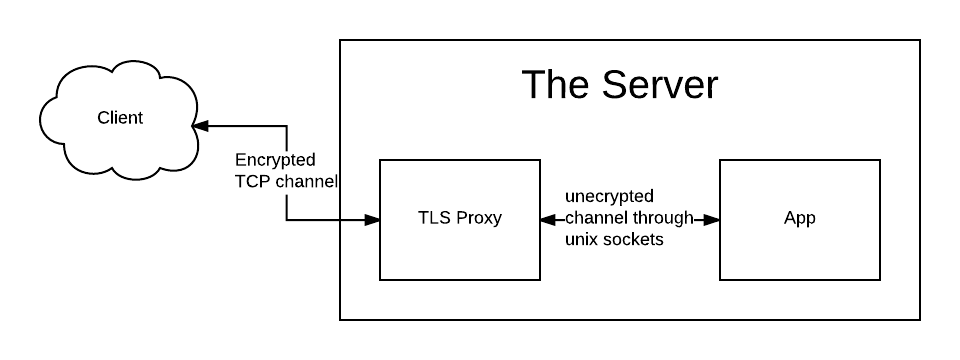
Design for a TLS terminator proxy
- The TLS proxy listens on a given port
- Clients communicate via TLS with the proxy
- Proxy decrypts and forwards the request to the application via Unix sockets
- Application responds
- Proxy re-applies encryption and sends it back to the client.
Rust Implementation
Since Rust ecosystem has only started to dip its toes in asynchronous IO with tokio I figured I should see what all the fuss was about.
In the end, while I was satisified with the result, the labor involved in getting code correct took a significant amount of time. I don’t think I have ever written code slowly. This makes sense though, I don’t ever write networking code this low, so it should take me longer as I figure what is needed to satifiy the compiler. The meat of my implementation was taken from the official tokio repo. TLS was achieved through a combination of tokio-tls and native-tls. Since I only care about the Linux use case, I needed to extend the functionality of native-tls to allow users of the library additional customizations for openssl.
Proxy App Code
I needed a server that would satisfy the following benchmark requirements:
- Have a mode to serve only HTTP requests
- Have a mode to server only HTTPS requests
- Have a mode where the server listens on a Unix socket for HTTP requests
- Be able to saturate multiple CPUs
I went with nodejs. Go probably would have been a good choice too, but I’m still not comfortable with Go build tools. An interesting note is that nodejs also uses openssl for crypto tasks, so whatever speed differences will most likely be due to the overhead of interacting with openssl.
The server will simply echo back the request data, which will give us a good sense of what overhead TLS constitutes.
Below is the code for the server. There are zero dependencies, which I reckon is quite an achievement in javascript land!
const fs = require('fs');
const http = require('http');
const https = require('https');
const cluster = require('cluster');
const sock = '/tmp/node.sock';
if (cluster.isMaster) {
// Since unix sockets are communicated over files, we must make sure the
// file is deleted if it exists so we can open the socket
if (fs.existsSync(sock)) {
fs.unlinkSync(sock);
}
// Create as many processes as provided on the commandline
const cpus = parseInt(process.argv[3]);
for (let i = 0; i < cpus; i++) {
cluster.fork();
}
} else {
// We're going to respond with every request by echoing back the body
const handler = (req, res) => {
req.pipe(res);
};
// Callback to let us know when the server is up and listening. To ease
// debugging potential race conditions in scripts
const listenCb = () => console.log('Example app is listening');
const arg = process.argv[2];
switch (arg) {
case 'sock':
http.createServer(handler).listen(sock, listenCb);
break;
case 'http':
http.createServer(handler).listen(3001, listenCb);
break;
case 'https':
const sslOptions = {
key: fs.readFileSync('key.pem'),
cert: fs.readFileSync('cert.pem')
};
https.createServer(sslOptions, handler).listen(3001, listenCb);
break;
default:
throw Error(`I do not recognize ${arg}`);
}
}
The script is invoked with
node index.js <http|https|sock> <#cpus>
One thing I noticed is that when I simply had the server res.send("Hello World") it would be about at least ten times faster (1 - 5ms) than the equivalent echo of the same request body (50ms). I’m not sure if the act piping http streams causes a lot more work (eg. the request body doesn’t even need to be parsed, etc). A brief internet search turned up nothing, so I’m not going to worry about it. EDIT: Turns out I ended up writing a post about this!
CPU Affinity
I tried something that I have never done before when it comes to benchmarking. I ran the benchmarking software (wrk) on the same box as server. Before anyone gets up in arms, let me introduce you to CPU affinity. In linux, one can set which CPUs a process can run on. By setting the proxy and the server to the same CPUs, it would be representative of them running on the same box – competing for the same resources. Wrk is set to a mutually exclusive set of CPUs.
Invoking taskset will control what CPUs are used:
taskset --cpu-list 0-2 node index.js http 3
Caveat, the kernel can still schedule other processes on the mentioned CPUs. To force the kernel to ignore certain CPUs(so that only your process is using that CPU), look into booting your kernel with the isolcpus option.
Benchmarking Script
Our script will have three different configurations:
- http: A nodejs server listening for HTTP requests on 3001
- https: A nodejs server listening for HTTPs requests on 3001
- tls-off: A nodejs server listening for HTTP requests on
/tmp/node.sockwith our proxy listening on 8080.
Each configuration will be ran five times for each body size.
#!/bin/bash -e
# This script will use all the cores on the box
CPUS=$(nproc --all)
# This is the directory where the TLS proxy is stored, the code is not
# currently open sourced but is included in the script for completeness.
# The command is ran on the CPUs as the application
RUSTTLS_DIR=../projects/rustls-off
RUSTTLS_CMD="taskset --cpu-list 0-$((CPUS - 2)) target/release/rustls-off config.toml"
# Node server created from the javascript posted earlier
NODE_DIR="../projects/test"
NODE_CMD="taskset --cpu-list 0-$((CPUS - 2)) node index.js"
# Benchmarking command. It uses only a single thread, as a single thread was
# able to saturate three server CPUs. Strangely enough, anything lower than
# 3000 connections wouldn't saturate anything (node is bottlenecked on something,
# but I'm not sure what)
WRK_CMD="taskset --cpu-list $((CPUS - 1)) wrk -t1 -c3000 -d30s"
# We'll be creating a Lua file to customize benchmarking. The Lua file will
# be deleted on completion
LUA_FILE=$(mktemp)
trap "rm -f $LUA_FILE" EXIT
# We're going to to test request bodies that are of varying sizes
for BODY_SIZE in 10 100 1000 10000; do
cat > $LUA_FILE <<EOF
wrk.method = "POST"
wrk.body = string.rep("a", tonumber(os.getenv("BODY_SIZE")))
done = function(summary, latency, requests)
io.write(string.format("%s,%s,%d,%d,%d,%d,%d,%d\n",
os.getenv("CONFIG"),
os.getenv("BODY_SIZE"),
summary.requests,
latency.mean,
latency.stdev,
latency:percentile(50),
latency:percentile(90),
latency:percentile(99)))
end
EOF
# Each body size benchmark will be repeated five times to ensure a good
# representation of the data
for i in {1..5}; do
echo "Body size: $BODY_SIZE, iteration: $i"
pushd $NODE_DIR
$NODE_CMD http $((CPUS - 1)) &
NODE_PID=$!
popd
# Must sleep for a second to wait for the node server to start
sleep 1
CONFIG=http BODY_SIZE=$BODY_SIZE $WRK_CMD -s $LUA_FILE http://localhost:3001 | \
tee >(tail -n 1 >> tls-bench.csv);
kill $NODE_PID
pushd $NODE_DIR
$NODE_CMD https $((CPUS - 1)) &
NODE_PID=$!
popd
sleep 1
CONFIG=https BODY_SIZE=$BODY_SIZE $WRK_CMD -s $LUA_FILE https://localhost:3001 | \
tee >(tail -n 1 >> tls-bench.csv);
kill $NODE_PID
pushd $NODE_DIR
$NODE_CMD sock $((CPUS - 1)) &
NODE_PID=$!
popd
pushd $RUSTTLS_DIR
$RUSTTLS_CMD &
RUSTTLS_PID=$!
popd
sleep 1
CONFIG="tls-off" BODY_SIZE=$BODY_SIZE $WRK_CMD -s $LUA_FILE https://localhost:8080 | \
tee >(tail -n 1 >> tls-bench.csv);
kill $NODE_PID
kill $RUSTTLS_PID
done
done
Results
Here are the median response times graphed for our three methods across multiple body sizes.
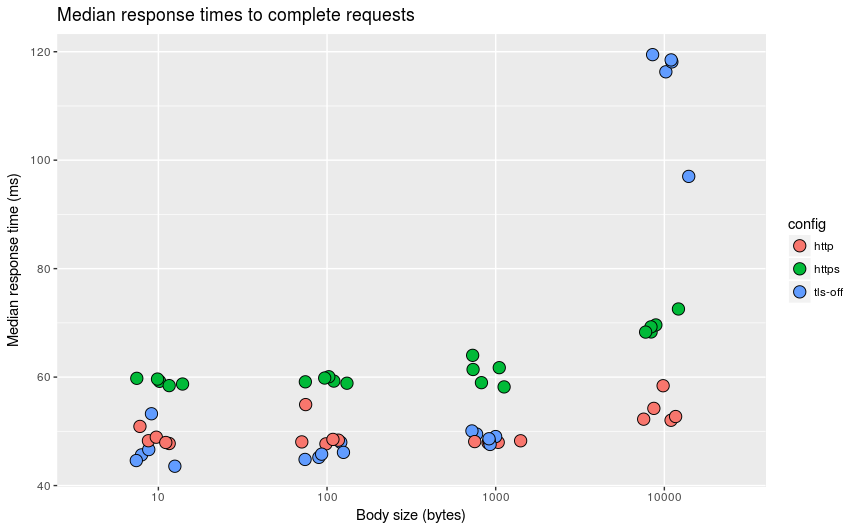
Results for TLS Termination
library(tidyverse)
library(readr)
df <- read_csv("tls-bench.csv",
c("config", "size", "requests", "mean", "stdev", "p50", "p90", "p99"))
df <- mutate(df,
mean = mean / 1000,
stdev = stdev / 1000,
p50 = p50 / 1000,
p90 = p90 / 1000,
p99 = p99 / 1000)
ggplot(df, aes(factor(df$size), p50, fill=config)) +
geom_jitter(size=4, width=0.15, shape=21) +
xlab("Body size (bytes)") + ylab("Median response time (ms)") +
ggtitle("Median response times to complete requests")
At low body sizes, the TLS proxy beats the HTTPs configured nodejs server handily, and even manages to beat the HTTP version (does this mean that Rust has a better TCP stack than node!?). As request size increase, our proxy does worse and worse. Why is that? Well, I’ve been keeping a secret. The proxy (so far) is only single threaded! As request size increases the amount of time needed to encrypt and decrypt requests grows and this computationally expensive task is bottlenecked one core. I reached out to the tokio community and they’ve given men a few ideas on how to incorporate multiple cores.
Open Source?
I’m normally a proponent of open sourcing a lot of my material, but this is still very experimental and I wouldn’t want anyone to get any other impression. This is just a small excercise in Rust and Tokio! There are a bunch of features I want to play with (I mentioned metrics and logging in the beginning), and if it starts to look good, I’ll let the world see it.
Comments
If you'd like to leave a comment, please email [email protected]