
Wasm and Native Node Module Performance Comparison
Published on:Table of Contents
Deploying code via Wasm is convenient as one can run the same code in the browser, nodejs, or via one of the several Wasm runtimes. What, if any, performance is sacrificed for this convenience? I demonstrate the tradeoffs in a real world example where I can take Rust code and benchmark the performance difference between running it as a node native module and Wasm compiled under varying configurations.
This article will specifically focus on Wasm runtime implemented V8 (ie: nodejs). Using Wasm in nodejs is extremely convenient and I don’t want to lose convenience by hooking up an additional runtime. Truthfully, I don’t think much is lost with these exclusions as the performance verdict from Benchmark of WebAssembly runtimes - 2021 Q1 is “just use Node” so we will.
Let’s start with the graph and use the rest of the article to break it down.
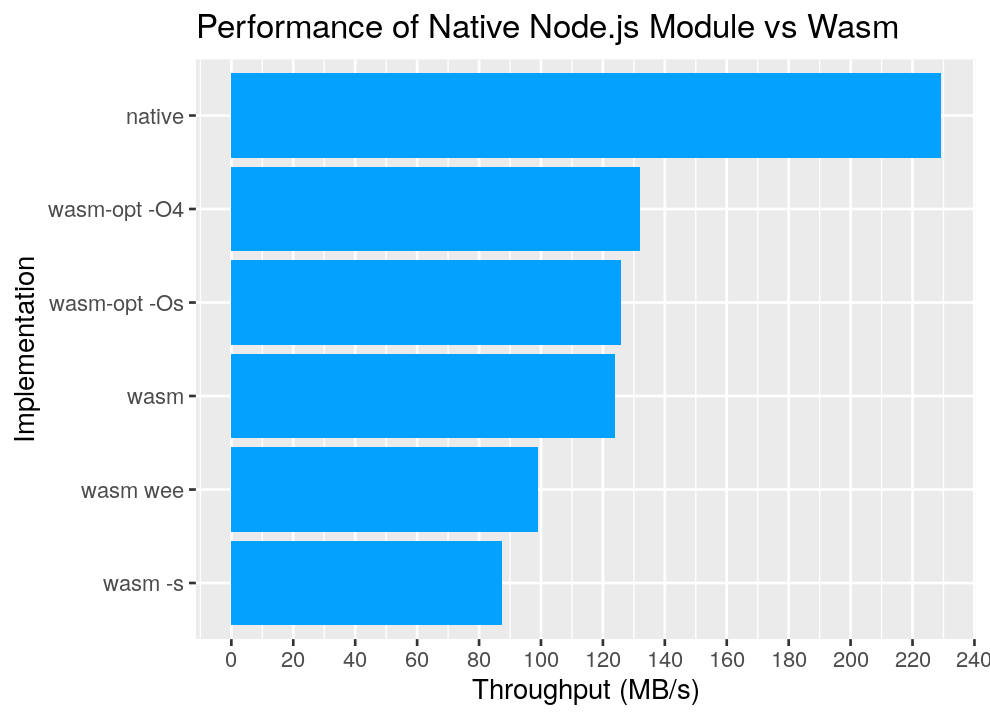
Bar chart of native performance vs wasm implementations
The main takeaway: in this benchmark, the native nodejs module is approximately 1.75x-2.5x faster than the Wasm implementations. That the V8 Wasm engine can get so close to native performance is an amazing achievement, but the performance increase of native modules can be well worth it.
Implementations:
native: A node native module exposed with napi-rswasm: project compiled in release mode (ie:--release)wasm -s: projectopt-levelset to optimize for binary size (sometimes smaller code is faster code, but not in this case)wasm wee: Switch the allocator to wee alloc to demonstrate the importance of memory allocations in this benchmark (the wee allocator is geared towards use cases where allocations are kept to a minimum)wasm-opt -Os: Take the output from thewasmstage and run it throughwasm-opt -Oswasm-opt -O4: Take the output from thewasmstage and run it throughwasm-opt -O4
Let’s break down the benchmark so that you can be an informed reader.
Benchmark
Earlier I called the benchmark real world. The code iterates through a zip file, inflates the entries, parses a format similar to JSON, deserializes it to an intermediate state, and performs calculations on said state before returning an answer. It looks similar to the code below (no need to understand it, but gives you an idea of some steps – the benchmark code wasn’t worth creating an open source project for, but the crate in question is open source)
fn parse_file(data: &[u8]) -> Result<MyOutput, Box<dyn std::error::Error>> {
let reader = Cursor::new(data);
let (save, _) = eu4save::Eu4Extractor::extract_save(reader)?;
let query = eu4save::query::Query::from_save(save);
let owners = query.province_owners();
let nation_events = query.nation_events(&owners);
let player = query.player_histories(&nation_events);
let initial = player
.first()
.map_or_else(|| String::from("UKN"), |x| x.history.initial.to_string());
Ok(MyOutput { initial })
}
This real world benchmark is in contrast to smaller benchmarks that can be tailored to favor Wasm or native code. For instance the native version of the isomorphic highwayhash implementation is over 10x faster than the Wasm version due to the availability of hardware intrinsics like AVX2 to native code.
To give a better idea of how much more code the real world project executes: the highwayhash wasm payload is 16 KB while the benchmarked wasm is 1.2 MB – a 75x increase. So lots of steps and variations in instructions that the native and Wasm implementations need to handle.
Some additional minor benchmarking details:
- node v16.3.0
- wasm-opt version 101
- benchmarks do not include time to load and compile wasm
Benchmark Backdrop
I did want to take a brief moment to talk about the impetus of this benchmark. I have an app where the backend is not the main show. The main show is the frontend where I use Rust compiled to Wasm to analyze large files (up to 100 MB uncompressed) client side. These files are saves from a game and if the user chooses they can upload the save to share with others. The backend verifies the upload and extracts a few pieces needed to be stored in a database. Since the backend needs to parse this file, any latency improvements for the user to see the successful upload is welcomed.
The great thing about Rust is that both the frontend and the backend use the same code. It seemed intuitive then to expose the backend behind a Rust API. I chose the warp web framework. It’s nice. It works. And I still use it. Though a train of thoughts crept into my head: since Rust web frameworks aren’t geared towards a batteries included approach to development – how much am I reinventing? Outside the parsing, the my app’s API is relatively simple: query redis, query the database, upload to s3, cookie and token authentication. How much am I reinventing incorrectly or insecurely? I think everything is secure and correct, but I kinda don’t want to think. The API is not the exciting part of the project.
So I started playing a bit. I extracted the Rust logic into a shared library which allowed it to be interoperable with a ASP.NET Core Web API sample. Then I wanted to embed it in nodejs server, which is how we arrived here. I didn’t know how much faster node native modules were for my use case. Now I do.
In my eyes, my bet on Rust is still vindicated even if I decide to migrate away from a Rust web framework. Rust has allowed me to build the exciting parts of the project in a performant, lightweight, developer friendly fashion that can be embedded anywhere.
Appendix
Code used to generate graph:
library(tidyverse)
library(readr)
# Number of inflated bytes processed
inflated <- 66607090
df <- read_csv("./bench-data.csv")
df <- mutate(df,
throughput = inflated / (ms / 1000) / (1000 * 1000)
)
ggplot(df) +
stat_summary(aes(reorder(implementation, throughput), throughput),
position="dodge2",
geom = "bar",
fill = "#04A1FF",
fun = max) +
scale_y_continuous(breaks = pretty_breaks(10)) +
expand_limits(y = 0) +
xlab("Implementation") +
ylab("Throughput (MB/s)") +
ggtitle("Performance of Native Node.js Module vs Wasm") +
coord_flip()
ggsave('bench-node-wasm.png', width = 5.5, height = 4, dpi = 180)
Comments
If you'd like to leave a comment, please email [email protected]