
Pitfalls of React Query
Published on:Table of Contents
Tanstack Query, (née React query for the purposes of this post) is a staple in async state and data fetching management. In addition to saving me from reimplementing similar caching mechanisms and fine grained updates, it was also the first library that solidified the concept of client vs server state, and how they are fundamentally different. Nothing is without tradeoffs, so I wanted to shed light on some potential pitfalls, not to disparage React Query usage, but to increase awareness.
Performance
Use useQuery liberally but not excessively
The useQuery hook is convenient and ergonomic to such an extent that it is possible to overuse to the detriment of render performance.
React Query starts to show a performance impact when one finds themselves with hundreds or thousands of query subscribers. A couple Github discussions have noted this, and an internal thread at my day job contains a flamegraph where React Query dominates profiles.
We can make a quick, contrived example to demonstrate this. Let’s create 1,000 components that listen on different parts of the same query, where every time the query is sent, an entry changes.
let count = 1;
const myEndpoint = () => {
const result = new Array<number>(1000).fill(0);
result[5] = count++;
return Promise.resolve(result);
};
function Row({ index }: { index: number }) {
const query = useQuery({
queryKey: ['example'],
queryFn: myEndpoint,
select: (data) => data[index],
});
return <li>{query.data}</li>;
}
function App() {
return (
<ul>
{new Array(1000).fill(null).map((_, i) => (
<Row key={i} index={i} />
))}
</ul>
);
}
Now let’s compare it to the version where the query is hoisted up and data is passed down.
function Row({ data }: { data: number }) {
return <li>{data}</li>;
}
function App() {
const query = useQuery({
queryKey: ['example'],
queryFn: myEndpoint,
});
return (
<ul>
{(query.data ?? []).map((data, i) => (
<Row key={i} data={data} />
))}
</ul>
);
}
Using the React <Profiler>, I recorded the duration it takes the hoisted and unhoisted versions to initially render and to reactively update when the query changes one element.
Here is a graph of the timings with a third entry for jotai that we’ll talk about.
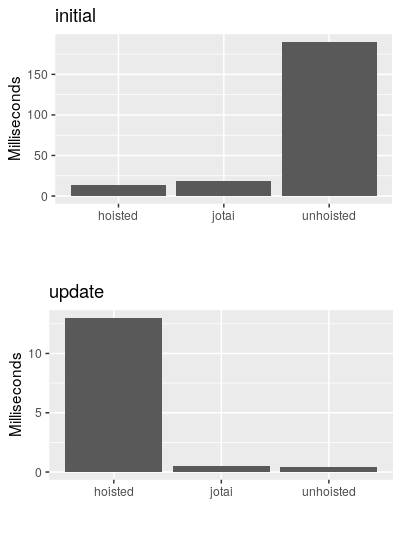
Profile bar graph
The profiler shows that the hoisted query has a quick initial render but slow update, while the unhoisted one had the opposite behavior: very slow initial render with fast updates.
What is the deal with the third bar in the graph, which seems to have fast initial initial renders and updates?
Lighter weight fine-grained updates
What if it’s too awkward to drill the data and fine grained updates are still required for individual data points? A motivating example would be feature flags, which are a cross cutting concern and can be represented by a server response that contains many independent pieces of data.
Aside: some may say that feature flags aren’t server state and are really a snapshot of an application for the duration of the session. Afterall, how often do feature flags change? I agree with the sentiment, but quickly spot checking some feature flag SDKs (Growthbook and PostHog), they provide ways for feature flags to be refreshed, so it’s something worth considering.
If having our component listen on the feature flag query is potentially too expensive, let’s introduce another state manager that allows for fine grained reactivity. In the example below, jotai is used, but any is fine.
import { atom, useAtomValue, useAtom, Atom } from 'jotai';
import { splitAtom } from 'jotai/utils';
const myDataAtom = atom<number[]>([]);
const myDataAtoms = splitAtom(myDataAtom);
function Row({ atom }: { atom: Atom<number> }) {
const datum = useAtomValue(atom);
return <li>{datum}</li>;
}
function App() {
const query = useQuery({
queryKey: ['example'],
queryFn: myEndpoint,
});
const [myData, setMyData] = useAtom(myDataAtom);
const entries = useAtomValue(individualAtom);
// STATE SYNCHRONIZATION
useEffect(() => {
if (query.data) {
setMyData(query.data);
}
}, [query.data, setMyData]);
return (
<ul>
{entries.map((x) => <Row key={`${x}`} atom={x} />)}
</ul>
);
}
The earlier benchmark result can speak for itself, so we can conclude that Jotai has a lighter weight reactivity mechanism that can be useful when faced with an otherwise excessive amount of useQuery.
But doesn’t the solution leave something left to be desired? We have a state synchronization step between two state managers. It feels impure. We now have a render where the data from useQuery won’t match our local state and could be a source of bugs. It muddies the waters between server state and client state, and if you recall from the opening paragraph, it generally behooves us to treat these types of state as fundamentally different.
But sometimes practicality trumps purity. And the previously available callbacks on query objects were removed for good reason.
There is a Jotai extension that creates a bridge to React Query. Even if it was perfect, adding a dependency to bridge two 3rd party dependencies is far and away the riskiest dependency there is, as isolating problems becomes an exercise in frustration untangling the two in order to submit any bug reports.
But let’s say the intermediate unsynchronized render state is particularly bothersome. There are two ways we can address it:
- Create a query client with a cache that synchronizes the query.
- Use the “internal”
QueryObserverAPI
Option 1 suffers from not creating an active query, so would need to place a dummy query somewhere that could look out of place.
For option 2, we’d want to make sure that our synchronization channel isn’t overused, as we’re re-introducing the query callbacks with stronger guarantees.
let instances = 0;
function useDataSync() {
const setMyData = useSetAtom(myDataAtom);
const queryClient = useQueryClient();
useEffect(() => {
instances += 1;
if (instances > 1) {
throw new Error('did not expect more than one instance');
}
const observer = new QueryObserver(queryClient, {
queryKey: ['example'],
queryFn: myEndpoint,
});
observer.subscribe((x) => {
if (x.status === 'success') {
// Use flushSync in case there is an instance of `useQuery`
// for the same query key that fired at the same time.
// Otherwise it is unecessary.
flushSync(() => setMyData(x.data));
}
});
return () => {
instances -= 1;
observer.destroy();
};
}, [queryClient, setMyData]);
}
But we have achieved our goal! In testing, the query cache, the backing atom, and any useQuery result were in sync for every render.
So we can say that when reaching for fine-grained updates, it can be beneficial from a performance standpoint to use a lighter weight observer offered by jotai and other state solutions.
Waterfalls
We talk about how we can optimize hydration, resumability, islands, partial hydration, reducing javascript bundles, and different performance tricks on payload.
I’ll tell you right now, waterfalls are singly more important than all of those put together.
Ryan Carniato (creator of SolidJS) - Don’t Go Chasing Waterfalls
I’d be remiss if I didn’t include a section on waterfalls in a performance section on data fetching.
I recommend listening to Ryan talk through the mental model, I don’t have much to add.
The React Query docs even call out waterfalls as the biggest footgun:
The biggest performance footgun when using React Query, or indeed any data fetching library that lets you fetch data inside of components, is request waterfalls
Component based data fetching is a prime suspect for waterfalls and yet React Query makes data fetching in components so easy that one is almost tricked into doing so!
Going back to the first section’s example on feature flags, where we hoisted data fetching for rendering performance. We should ask ourselves how our solution would change if there was zero overhead to embedding the query as deep in the tree as possible. We would find ourselves in a waterfall situation, as our feature flags would probably only send the query after other requests blocked rendering. The good news is we can solve this problem with prefetching and React Query has an entire guide on the topic.
Waterfall-aware optimization isn’t a fringe topic. Next.js is doing their part championing multiple methods for hoisting as much data fetching as possible to the route level.
For more information but from a slightly different angle (the <Suspense> angle), consider looking into the topic of fetch-as-you-render vs fetch-on-render. While not technically the same, it’s the same dichotomy as route vs component level fetching.
Request deduplication with dynamic options
A major selling point of React query is that it will deduplicate multiple requests for the same query key by essentially deferring to the inflight request that was issued first. Sounds simple enough.
What happens when we issue the same request from a child and parent component simultaneously but with different options?
const myEndpoint = ({ meta }) => {
console.log(meta.name);
return Promise.resolve('hello world');
};
function Child() {
useQuery({
queryKey: ['example'],
queryFn: myEndpoint,
meta: { name: 'child' },
});
return <div>Child</div>;
}
function App() {
useQuery({
queryKey: ['example'],
queryFn: myEndpoint,
meta: { name: 'parent' },
});
return <Child />;
}
First question, when our app is first rendered, what is logged?
The correct answer is “child” because queries are sent after a component is mounted and children are mounted before parents, so the request in parent is deduplicated to the inflight child request.
But what happens to the options defined in the parent query? Asked another way, what is logged when a button is clicked to invalidate the query?
<button
onClick={() => {
client.invalidateQueries({ queryKey: ['example'] });
}}
>
Click me
</button>
The answer depends on the React Query version you are using.
- Version v4.36.1 continues log to “child”
- Version v5.28.4 will log “parent”
Aside: I hope your application isn’t relying on these specific behaviors.
It looks like the intended behavior is that the last write wins for query options but that the latest options may not apply to the current inflight query.
That is until we look at the window focus refetching behavior, where 5.28.4 reverts back to logging “child” until the invalidation button is clicked. This seems like a bug, but I am unsure. I can see an argument for a window focus to run queries in the order that they were originally registered.
Retries
If your head is spinning. Let’s add more centripetal force with retries with an endpoint that fails.
const myEndpoint = ({ meta }) => {
console.log(meta.name);
return Promise.reject(new Error('hello world'));
};
Given the following sequence, what is logged for each attempt?
- Attempt #1
- Attempt #2 (Retry Attempt #1)
- Query cancel + invalidation
- Attempt #3
- Window Refocus
- Attempt #4
Answer (which varies by React Query version):
- “child”
- “child”
- “parent”
- “child”
This confirms that retries use the same options from the first request in future retries until success or failure, regardless if they are the latest options.
Dynamic invalidate
Let’s look at a single query that has dynamic options.
const myEndpoint = ({ meta }) => {
console.log(meta.status);
return Promise.resolve('hello world');
};
function App() {
const [status, setStatus] = useState(false);
const client = useQueryClient();
useQuery({
queryKey: ['example'],
queryFn: myEndpoint,
meta: { status },
});
return (
<button
onClick={() => {
setStatus(true);
client.invalidateQueries({ queryKey: ['example'] });
}}
>
Click me
</button>
);
}
What is logged in the following sequence:
- 1st query
- Query after invalidation
- Additional subsequent invalidations
- Window refocus
Answers:
- “false”
- “false”
- “true”
- “true”
These answers, again, differ on the React Query version in use!
But the most important aspect I want the example to convey is that query invalidation is triggered immediately when invoked due to how React state updates work. When the query is first invalidated, it hasn’t yet seen the updated status state. Subsequent renders update the effective options when executed.
That means if we are bent on seeing the updated status on first invalidation, one solution is to leverage flushSync.
return (
<button
onClick={() => {
flushSync(() => {
setStatus(true);
})
client.invalidateQueries({ queryKey: ['example'] });
}}
>
Click me
</button>
);
DIY updates
My recommendation in order to preserve a consistent behavior across React Query versions is to write React Query options such that they are functions that can reference the latest values even for retry attempts that reuse the same options. That way you are always in full control.
The example below retries until the user presses the button.
const myEndpoint = () => {
console.log('querying');
return Promise.reject(new Error('oh no'));
};
function App() {
const keepRetryingRef = useRef(true);
useQuery({
queryKey: ['example'],
queryFn: myEndpoint,
retryDelay: 1000,
retry: () => keepRetryingRef.current,
});
return (
<button
onClick={() => {
keepRetryingRef.current = false;
}}
>
Click me
</button>
);
}
I highly recommend the technique shown above with your state manager of choice so that one doesn’t need to rely on variable React Query behavior, as the ambiguity in behavior makes it clear that easy is not better than simple.
It’s hard to wrap one’s head around this behavior (much less maintain it for the future) even for a React Query maintainer who misunderstood these examples and started to insinuate my lack of React understanding before coming around.
The conversation was about how only a subset of React Query options were dynamic but for the sake of brevity I don’t want to add yet another example of how React Query options behaviors differ depending on the React Query version, as my recommendation still remains the same: use functions.
Staleness
Not all React Query options accept functions, so let’s look at a dynamic staleTime
const myEndpoint = () => {
console.log('executing');
return Promise.resolve("hello world");
};
function App() {
const [status, setStatus] = useState(false);
useQuery({
queryKey: ['example'],
queryFn: myEndpoint,
staleTime: status ? Infinity : 0,
});
return (
<button
onClick={() => {
setStatus(true);
}}
>
Click me
</button>
);
}
We should have two questions:
- Will the dynamic staleTime be effective?
- How many times will our query function log?
Answers:
- A dynamic
staleTimedoes get picked up (verify using the React Query devtools). - Our query function only logs once! The previous result is still considered fresh with our infinite staleTime. You’ll want to invalidate the query if you need to force an update.
For those that think they understand how dynamic options work, what is the resulting staleTime when we have multiple listeners with different staleTime values?
const myEndpoint = () => Promise.resolve("hello world");
function Child() {
useQuery({
queryKey: ['example'],
queryFn: myEndpoint,
staleTime: 0,
});
return <div>Child</div>;
}
function App() {
useQuery({
queryKey: ['example'],
queryFn: myEndpoint,
staleTime: Infinity,
});
return <Child />;
}
In a twist, the effective staleTime is zero. It’s zero even if we swap the parent and child values.
My hypothesis is that the effective staleTime is the most pessimistic value between all enabled listeners. I emphasize “enabled” as that behavior was recently changed in React Query v5.27.3.
Thankfully the number of options that lack a function argument are few, as I don’t know how many more of these behaviors I can test before seeing my mind crumble.
It would be nice to see everything seen here today documented, so I don’t need to do all the necessary observations myself, form hypotheses on what the intended behavior should be, and risk justifying erroneous behavior.
While this may seem like a lot to take in and there is room for improvement, at least it is better than implementing a analogous React Query solution yourself.
Comments
If you'd like to leave a comment, please email [email protected]