
Designing a Decaying Leaderboard with Redis
Published on:Table of Contents
The EU4 achievement leaderboard and save file analyzer, Rakaly, has several requirements when it comes to maintaining the leaderboard:
- There are hundreds of achievements in EU4 and each one should have its own leaderboard (eg: forming Italy is much quicker than owning the world).
- Every EU4 patch can introduce different gameplay mechanics that can significantly impact how quickly an achievement can be acquired, so it’s important to distinguish submissions by the patch the game was played on.
- Preference should be given to players who submit on the latest patch to avoid the leaderboard from getting stale with submissions from old patches – hence the term “decaying leaderboard”. This means that when a new patch releases, all prior submissions incur a minor penalty (and the older the patch, the more the penalties stack)
- If two players submitted runs with the same score on the same patch, the player who submitted first should take precedence
- The same run can be submitted at multiple dates and the best date for each achievement will be used.
- Keep things as simple as possible. No need to dip into writing Redis Lua scripts if possible.
This is all accomplished with Redis
The Schema
Like all database schemas, forethought must go into how an app will leverage Redis. While Rakaly keeps Postgres as the source of truth, Redis is used to quickly return the leaderboard thanks to sorted sets. Redis is also used in Rakaly for other tasks such as tracking user sessions and metrics.
In Redis, every achievement is a sorted set that is broken down by the patch version. For instance, the achievement with the ID of 108 (corresponding to Hindustan or Bharat owning London among other historical British holdings) for version 1.29 of EU4 would be represented as raw_score:108:1.29. Broken down graphically:
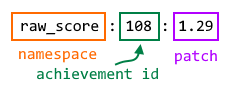
Storing each achievement for each version of the game in a sorted set
Sometimes is off putting for proponents of static typing to work with stringly typed keys with fields delimited with colons, but since it’s a widely used practice recommended by Redis, it’s just something one has to tolerate.
Now that we know how to lookup the name of the leaderboard, the below diagram details the key plus the contents of the set:
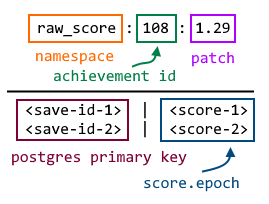
Schema for an achievement leaderboard for a given patch
The set members probably don’t need too much of an explanation. They are primary keys to the postgres database so that when Redis returns a set of save ids, they are quick to look up in Postgres to retrieve the full set of data related to that save.
The score will need more of an explanation as it is a combination of the number of ingame days it took to complete the achievement (a whole number) plus the epoch timestamp of the submission is stored as the fractional part. For instance, if I have a save where I completed an achievement in 100 ingame days and I submitted it on September 13th, then the entry would look like:
100.1600000000
By recording the timestamp as a fraction, players who submit a save with the same achievement with the same number of ingame days will have a worse rank as their epoch time stored in the fractional part will be greater and thus sorted lower down. Some call this temporal leaderboards.
It should be noted that storing the score like this may be controversial. We’ll dive deep into the controversy in a bit. Before that, we need an overarching achievement leaderboard that covers all patches. EU4 was released in 2013. In that time, there have been 30 major patches changing gameplay dramatically. It’s desirable to highlight extraordinary saves that stand the test of time but also emphasize accomplishing achievements using new strategies allowed by the latest patch. This is done through a patch tax. The tax can be arbitrary but I’ve settled on 10% (not compounding) per patch a submission is behind the latest patch.
The solution is to create another sorted set for a given achievement that contains the after-tax scores
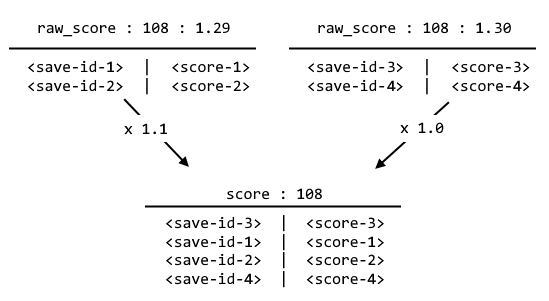
Full schema for an achievement leaderboard
As you might imagine there are a lot of leaderboards, but it tends to work well. When a submission arrives, calculate the before and after tax scores and ZADD it to all appropriate raw and aggregate leaderboards
The Decay
The previous section covered how to incorporate a new submission, but we still need to deal with the ramifications of a new patch: all prior submissions have a new tax rate. Scores that previously were taxed at 10% should be taxed at 20% to make way for new submissions.
Below is pseudo code for updating the aggregate leaderboard. The key is to use ZUNIONSTORE to apply a multiplicative factor on all the raw patch leaderboards.
MULTI
FOR key in SCAN MATCH "raw_score:*":
let [_, achievement_id, patch] = key.split(':')
let factor = calc_factor(patch)
ZUNIONSTORE `score:${achievement_id}` 1 key ${factor}
EXEC
While it may be implemented via lua with fewer roundtrips, my preference is keep the tax calculations in one place so that business logic isn’t scattered and risk an out of sync issue.
The Controversy
There are some cracks in the design of storing the epoch as the fractional digits of a score
When applying the old patch tax, the epoch fractional digits could cause a difference in the result of a score. For instance here are some calculations if we complete an achievement in 109 days on a patch that is twice behind the most recent patch (so the patch tax is 20%):
109 * 1.2 = 130.9925
109.1604341851 * 1.2 = 130.8
If truncating numbers, it’s quite close to 131 vs 130. This could have real ramifications in designs that want to keep the epoch part of the score invisible. I recommend to shift the epoch over an additional decimal place (or more). So our calculations become
109.01604341851 * 1.2 = 130.82
But we’re going to run into a different problem: loss of precision. Redis stores the score as a 64bit floating point number. This is not a problem for our examples thus far, as small scores have been used, but in EU4, it can take one up to 137384 days (November 11th 1444 to January 3rd 1821) to complete an achievement.
If we shifted the epoch over and tried to write out a submission that took 137384 days like so:
137384.01604341851
redis will record it as:
137384.01604341852
Boom! Loss of precision. To the leaderboard it now looks like the user submitted one second later than they actually did. Is this a problem? It’s hard to say, but I’m leaning towards that it is acceptable. The epoch is used as a tie breaker so one can say that the users that submitted the same score in the same block of time denoted by the loss of precision are ordered arbitrarily.
I believe the small window of time opened by the loss of precision to an arbitrary order is tolerable, but I understand this is use case specific. I know there are alternatives where two sets are used to record values: one set with the pure score and another set that orders all the players that achieved that score, but this extra layer of indirection is not worth it in my eyes if functionally the same can be represented by a single set.
Comments
If you'd like to leave a comment, please email [email protected]