
Backblaze B2 as a Cheaper Alternative to Github's Git LFS
Published on:Table of Contents
When cost optimizing, consider using Backblaze B2 over Github’s git LFS. B2 has a much more generous free tier compared to Github’s: 10x more storage (10GB vs 1GB) and 30x more bandwidth (30GB vs 1GB). Even after exceeding the free tier, Github’s git LFS still commands a 12x price premium. Before abandoning git lfs, there are several tips to keep in mind.
But first some background
Background
Working on Rakaly, the EU4 achievement leaderboard and save file analyzer, I’ve amassed a bit of collection of test cases (ie: save files) for regression testing. Each save file is 5-10MB compressed. Not overly large by themselves, but together they add up. I need a solution that makes the saves accessible for the tests but not bog down the repo or expose myself to hidden costs.
As an aside, if you’re interested in the behind the scenes for Rakaly, I’ve written more about before in My Bet on Rust has been Vindicated
Before open sourcing to Github, Rakaly was kept in a self hosted Gitea instance. The save files were kept in git lfs in Gitea and everything worked wonderfully. I highly recommend Gitea and continue to use it to this day, but since Github has a monopoly on the developer mindshare when it comes to open source, I migrated the Rakaly repo to Github.
Being the good open source maintainer that I am, I enabled CI via Github actions and ran regression testing on every commit on a half dozen platforms. Even with git lfs caching enabled, I exhausted Github’s git lfs free tier within 24 hours!
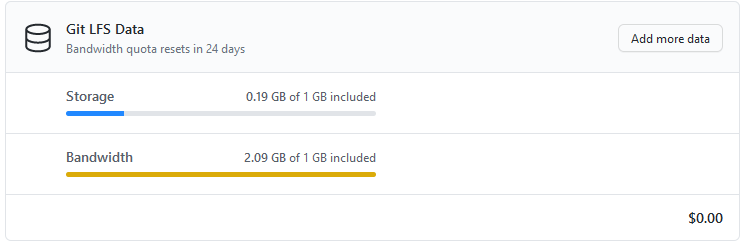
Github Git LFS bandwidth exceeded
A new solution was warranted. I briefly considered paying for a data package but a public git lfs repo seemed somewhat susceptible to drive by clones needlessly depleting the bandwidth. And Rakaly is a hobby project. I don’t make anything on it and probably won’t ever, so to go from paying Github $0 to $60 a year is an unpleasant thought.
The Solution with Backblaze B2
The solution that I implemented is to store all the save files in a Backblaze B2. It’s a public bucket so the code can pull the files on any machine without prior steps (and there is no need to install the git lfs client). The bucket doesn’t allow one to list objects to mitigate chances of data hoarders downloading everything in sight.
So here are the tests are written:
Create a utility method that declares what file (or files) that the test is interested in and use it like so:
let data = utils::request("eng.txt.eu4.zip");
This utility method has a few steps:
- Check if the file is present in the local disk cache (and if so return that)
- Else connect to the B2 instance with S3’s API
- Download said file
- Store file in the local disk cache
- Return downloaded file
Results and Thoughts
- Files uploaded to B2 must be immutable. Instead of overwriting a file, a new file with a different name should be uploaded else someone’s local disk cache will be stale. This may be able to be solved via md5sum, but I’m not too interested in complicating the solution at this time
- Prefer not deleting files uploaded to B2 so that past commits can still have their test cases run
- Best not run these regression tests in parallel else a race condition may occur for tests that use the same file. If the file isn’t cached, there is a chance that both retrieve the file (increasing bandwidth) and both interleave writes creating an abomination in the cache. This problem can be alleviated with atomic moves, but I prefer simple solutions until ugly problems rear their head.
- No wasted bandwidth or disk space. Only files that are needed to run a test are downloaded so if one doesn’t need to run a category of tests, then those files won’t be downloaded.
- With the ubiquity of S3 clients, this solution should be feasible to implement in any project
While the end result is that I’m paying $0 instead of $60+ a year, I’d still recommend defaulting to git lfs when possible as it’s hard to beat the solution that is integrated into git.
Other Solutions
There’s Gitlab, which I don’t believe has bandwidth limits on git LFS pricing but does have a repo size of 10 GB. This limit seems much more tolerable and decent compromise compared to Github. While Gitlab doesn’t have the same developer mindshare as Github, it at least has some (unlike a self hosted Gitea instance that I emigrated).
git-annex is another well maintained program to deal efficiently with large files. It predates git LFS and it can natively work with a wide array of backends, including Backblaze B2! When compared with the tooless approach of tests downloading and caching files on-demand, git-annex doesn’t have as low of a barrier to entry. Yes, I’m reinventing behavior that is already part of a larger tool, but I find spending an hour to eliminate a dependency a worthy tradeoff especially if this dependency only has beta support for Windows. If I was working on a team that was comfortable with git-annex and large binary files were central to the project (instead of merely test cases) then my recommendation would be to use git-annex. In the end, I value developer mindshare and a low barrier to entry more than a power tool.
Fork over the money to Github
Comments
If you'd like to leave a comment, please email [email protected]