
High Performance Unsafe C# Code is a Lie Redux
Published on:Table of Contents
I didn’t realize anyone but me visited this site, so imagine my surprise when I connected to the MySQL server powering the comments and saw that not only were there comments, but there was a highly constructive comment left by a Patrick Cash. He pointed out some serious flaws with the article, so I’m going to attempt to construct a comprehensive test.
Goal
To find the fastest method to read a Western (Windows 1252) encoded file scanner that has a maximum token limit.
Therefore the sensationalist title can be replaced with “Fastest method to create a string”
Introduction
Dealing with foreign characters is always a non-trivial task, and has been
written about before. So now that there is a basic understanding, I
would like to point out a statement that many who work with C/C++ and C# often
forget until they are burned. A char in C is not the same as a char in C#. The
former has a sizeof one byte and the other has a sizeof two. The reason for
C# having char be two bytes is explained succinctly in the standard.
Character and string processing in C# uses Unicode encoding. The char type represents a UTF-16 code unit, and the string type represents a sequence of UTF-16 code units (pp. 9).
Many developers can go quite a while without needing to know this fact. There
aren’t many situations where dealing with a string screams UTF-16
capabilities, which is a beautiful aspect of the .NET framework. It makes
globalization that much easier.
A problem arises when developers try to get smart. We’re cursed with perfectionism. Fast is not fast enough, so we try to think of the ways to milk every ounce of performance out of the code. I’ve been burned by this too many times. I always try to read a non-ASCII encoded file and transfer contents into a string byte by byte (read: byte), and I get burned when odd characters appear in the output. It is possible to read the file byte by byte and get the correct output with an intermediate step; however, I never think about that on the first iteration of the code.
With that out of the way, it is time to investigate the best method for satisfying our goal, which involves finding the fastest method for reading the contents of a Western encoded file. There are many methods available. At the byte level is FileStream, char level is StreamReader, and both of those can be bypassed in favor of calling the win32 api ReadFile. In case anyone was wondering why I am not considering BufferedStream, it is because ’there is zero benefit from wrapping a BufferedStream around a FileStream’ {% cite bufferedstream %}. After extracting the contents from the file there are two ways to process it, one using indicies and other using pointers.
Results
The test involved having each method read an approximately 50MB file.
The results:
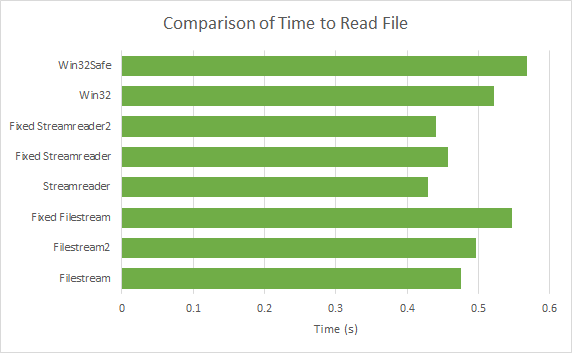
Comparison of Time to Read File
If I were to draw any conclusions from this picture it would be Keep It Simple Stupid (KISS). Notice how tried deviating from the most straightforward implementation for StreamReader and FileStream and that only resulted in worse performance. All the ‘fixed’ methods involved unsafe techniques, so using unsafe code in this context does not lead to performance gains, rather performance losses. I stick to the same conclusion that I found in the first version.
For more information regarding unsafe code and why it may result in slower code, read below.
Use of fixed
Fixing an array, in C#, tells the garbage collector (GC) to not move the array allocated on the heap, no matter what. It may seem like a statement that couldn’t harm performance but it is not uncommon for there to be performance degradation. The GC could see an opportunity to move the array to a more effective location, but since it is fixed, it is not allowed to. Eric Lippert, who, until just recently was a principal developer on the C# compiler team has written
[Fixing a variable] can really mess up the ability of the GC to efficiently manage memory, because now there is a chunk of memory it is not allowed to move
[I]f [the GC] sees a “fixed” local variable then it makes a note to itself to not move that memory, even if that fragments the managed heap. (This is why it is important to keep stuff fixed for as little time as possible.)
In addition, the fixed statement gets transformed into several lines of
Intermediate Language (IL), which come at a cost. One would then logically
deduce that hoisting statement outside of all loops would be best for
performance, however this is not guaranteed, as this would make the array
ineligible for GC optimizations longer. Follow the rule of thumb to always
benchmark. In this instance, hoisting the fixed outside loops saw about a 5%
improvement. Thus, I’m in disagreement with Eric on this one, as ‘fixing’ a
variable as close to its use is not always efficient.
Use of stackalloc
I doubt many C# programmers know that stackalloc is a keyword, and in unsafe
contexts I tend to declare most of my arrays with stackalloc, but what does it do? From the standard:
[A]n immobile local memory store is associated with each method invocation, and that
stackallocallocates memory out of that store. In a typical implementation, that store will be the call stack, but that’s an implementation detail.
In the event that the array can be allocated on the stack, it will be, otherwise it will be allocated on the heap per usual. Some people claim that allocating arrays on the stack will increase performance and that overhead is greatly reduced. I’m not sure what they’re talking about, but it’s clearly is not always the case. I’ll have to continue exploring unsafe code to see if there are uses that perform better than their managed counterparts.
Whatever others say, I use stackalloc so that I can avoid fixed.
Win32 API
I’m truly baffled why the Win32 methods didn’t perform better, especially
because in the C# 2.0 source code, they make the same win32 calls I do!
Granted, I wasn’t using C# 2.0, but I doubt there’s been severe changes to the
IO operations. In the source code, the only difference seems to be they call
fixed in the inner loop, which only adds to my confusion because that should
make it inefficient. I’ll have to defer to a Win32 expert as to why this is
happening, but my intuition says that skipping the middleman (FileStream) should
result in a more efficiency.
Epilogue
While reading the MSDN documentation on all the .NET streams, so I could better prepare this post, I ran across this:
When reading from a Stream, it is more efficient to use a buffer that is the same size as the internal buffer of the stream.
I took a look with ILSpy at the internals of FileStream and saw that the default buffer size was 4K and I was using a buffer size of 32K to read the data. Instantiating the filestream with the correct buffer size increased performance by 10%. It helps to read the documentation!
Comments
If you'd like to leave a comment, please email [email protected]
This perhaps true of reading files, but I have seen large performance improvements when using unsafe code to perform vector math, specifically bitwise operations over byte arrays exposed as uint or ulong arrays by creating pointer of these types to the byte array (enabling 4 or 8 simultaneous byte operations, respectively). The improvements have been from 2 to 3x. Not insignificant at all!
I was surprised by the substantial speed increase, when processing an image as a 2-dimensional array using unchecked pointers. someImage[rowIndex, colIndex] imposes two expensive operations: multiplication and array bounds checking. Multiplication is used to find the address of a pixel: pixelAddress = someImageAddress + (rowIndex * rowWidth + colIndex) * sizeof(pixel); With a pointer the operation becomes: ++ptr; or pixelAddress += sizeof(pixel); Two multiplications are avoided per pixel. The benefit is a significant performance gain. The cost is that the code becomes a mixture of 2-dimensional and ptr based references. Array bounds checking is done by the CLR. It is inadvisable to disable it, since the performance cost is small and the benefit of avoiding memory corruption is high. In unchecked code, the CLR does not check array bounds. The benefit is speed. The cost is a Managed assembly has the ability to corrupt any of its memory at any time. With un-managed code this is a known risk, but for what is otherwise managed code, memory corruption in its many forms will be a surprise to later maintainers. A good compromise in unchecked code is to add array bounds checking, at least for DEBUG builds.
Don’t use stackalloc as it is very slow (even slower than the heap using a fixed keyword to access it) , but use a static ThreadLocal with a fixed size. Replacing my unsafe method (using stackalloc) with a (safe) method using a static ThreadLocal, I was able to increase speed 11-times .
Minor correction: I was never the head of the C# team. It is easy to see how this confusion arises, because “principal developer” is a level title at Microsoft, I was one of several “principals” on the compiler team; there were Partner Architects and a Technical Fellow on the team as well who greatly “outranked” me.
Thank you for the correction, I’ve updated the sentence to now read “Eric Lippert […] was a principal developer on the C# compiler team […]”